Blog
Orbion Team
When AlphaFold-Multimer Gets Protein Complexes Wrong: Six Failure Modes Every Structural Biologist Should Know

A structural biologist runs AlphaFold-Multimer on a kinase-scaffold pair, gets a confident-looking heterodimer with ipTM of 0.74, and designs a panel of 18 interface mutants based on the predicted contacts. Six months and three rounds of expression, purification, and SPR later, none of the mutations disrupt binding. The "interface" was a hallucination—the real binding site sits 35 Å away on a surface AlphaFold-Multimer never sampled. This is not a hypothetical. Variants of this story now show up in retraction notices, in lab meetings, and in the supplementary material of papers that quietly walked back their original mechanistic claims.
AlphaFold-Multimer is a transformative tool, but it has well-characterized failure modes that no confidence score by itself will reveal. Knowing where it breaks is now as important as knowing how to run it.
Key Takeaways
Transient complexes (Kd > μM) are systematically harder for AlphaFold-Multimer than obligate complexes because the training distribution is dominated by stable, co-crystallized assemblies.
Stoichiometry is an input, not an output—if you assume a dimer when the true state is a trimer, even a "high-confidence" prediction is wrong by construction.
Conformational state is collapsed: AlphaFold-Multimer typically returns a single state (often the dominant one in the PDB), missing apo/holo, active/inactive, and allosteric alternatives.
Antibody-antigen prediction remains unreliable even at high ipTM; epitope success rates in blind benchmarks hover in the 20-30% range despite high overall scores.
Membrane protein interfaces are predicted in vacuum—lipid-mediated contacts, raft partitioning, and bilayer geometry are absent from the model.
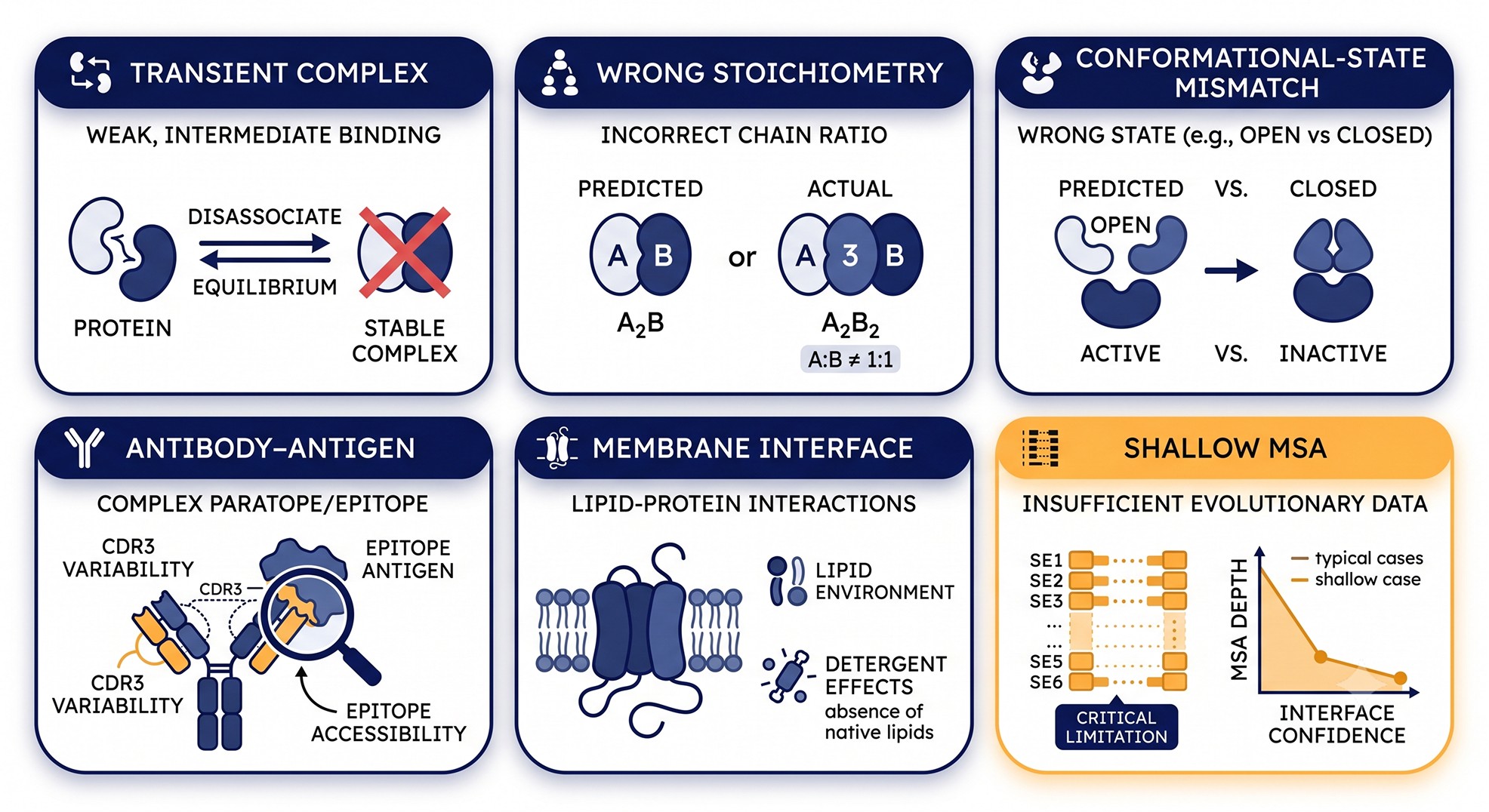
Why "Wrong" Has Six Flavors, Not One
The AlphaFold-Multimer manuscript (Evans et al., 2022) was disarmingly honest about scope. The model was trained on the PDB, which is enriched for stable, crystallizable, often-obligate complexes assembled under conditions amenable to structural biology. Anything outside that distribution—weak interactions, alternative conformations, lipid-embedded interfaces, fast-evolving immune complexes, novel host-pathogen pairs—drops the success rate sharply. The follow-up benchmarks (Yin et al., 2022; Bryant et al., 2022; Burke et al., 2023) quantified this. The headline number people quote—"~70% success on heterodimers"—averages across regimes where success is near 90% and regimes where it is near 0%.
The practical question for any working scientist is: which regime is my complex in? Below are the six dominant failure modes, what they look like in the output, and what to do instead.
Failure Mode 1: Transient and Weak Complexes (Kd > μM)
What goes wrong
AlphaFold-Multimer was trained to reproduce structures in the PDB. The PDB is overwhelmingly populated by complexes that survived purification, gel filtration, and crystallization—conditions that preferentially capture interactions with Kd in the nanomolar to low-micromolar range. Transient signaling complexes, enzyme-substrate Michaelis complexes, intrinsically disordered region (IDR)-mediated interactions, and low-affinity scaffolding contacts are heavily underrepresented.
The result: for weak complexes, AlphaFold-Multimer often produces one of three pathologies:
A high-confidence prediction that snaps to the strongest-affinity homologous interface in its training set (which may not be the relevant one).
A low-confidence prediction with high inter-chain PAE that is correctly flagged but not actionable.
A "best guess" that places the two surfaces in contact at a thermodynamically favorable but biologically incorrect site.
Bryant et al. (2022) and the Burke et al. (2023) human interactome benchmark both reported sharply lower DockQ scores for low-affinity interactions, with the latter noting that AlphaFold-Multimer's success rate on human binary interactions drops to roughly one in four when the partners are not from obligate complexes.
How to recognize it
ipTM in the gray zone (0.5-0.7) with intra-chain pTM still high. The model knows each chain folds; it is ambivalent about how they assemble.
PAE matrix is "patchy" in the off-diagonal blocks—small islands of low error surrounded by yellow/red regions.
Top-5 ranked models disagree on the interface. If model_1, model_2, and model_3 place the contact in geometrically distinct regions, none of them is reliable.
Sequence-level biology: the partners are known to be regulated by abundance or localization rather than affinity, or the interaction has only ever been detected by Y2H or proximity labeling.
Workaround
Run AlphaFold-Multimer multiple times with different random seeds and MSA subsamples and look for consensus rather than confidence. If the top model from each independent run places the interface in the same patch of residues, the prediction is far more credible than any single high-ipTM run. For genuinely transient complexes, structural prediction should be treated as hypothesis-generation, not validation—cross-link MS, HDX-MS, or NMR chemical shift perturbation experiments should drive the conclusion.

Failure Mode 2: Wrong Stoichiometry
What goes wrong
AlphaFold-Multimer does not predict stoichiometry; you provide it. If you submit two copies of chain A and one copy of chain B, you get an A₂B prediction. If the true assembly is A₃B₂, the prediction is wrong before the network even starts.
This is one of the most common silent failures in the literature. A researcher knows their protein from biochemistry as a monomer, predicts a 1:1 heterodimer with a binding partner, gets a beautiful interface, and never tests whether the true biological assembly is a higher-order oligomer. The off-target stoichiometry produces an interface that is geometrically plausible and even thermodynamically reasonable—but it is not the assembly that exists in the cell.
Yin et al. (2022) showed that for homomeric assemblies, providing the correct number of subunits is critical: predicting a trimer as a dimer produces a chimeric "best of both worlds" interface that satisfies dimer constraints but violates trimer symmetry. The resulting model is often misleadingly confident because pairwise contacts between any two subunits look correct.
How to recognize it
Known biochemistry contradicts the prediction—SEC-MALS, AUC, or native MS gives an apparent mass inconsistent with the assumed stoichiometry.
Symmetry axes are broken: the predicted assembly should be C₃ or D₂, but the model is asymmetric with unequal inter-chain interfaces.
Conserved interface residues sit on the "wrong" face of the protein—pointing into solvent rather than into another subunit.
The buried surface area per subunit is anomalously small, suggesting the model is missing additional protomers that would normally contribute interface area.
Workaround
Run a stoichiometry sweep. For a suspected oligomer, test A, A₂, A₃, and A₄ explicitly and compare ipTM, inter-chain PAE, and total buried surface area across stoichiometries. The correct stoichiometry usually produces a sharp peak in confidence. For hetero-assemblies, combine the sweep with biophysical data: SEC-MALS or mass photometry first, then prediction.
Failure Mode 3: Conformational State Mismatch
What goes wrong
Most proteins exist in multiple conformational states—apo vs. holo, active vs. inactive, open vs. closed, kinase DFG-in vs. DFG-out. AlphaFold-Multimer typically returns one state, and the choice is biased toward whatever state dominates the training distribution. For well-studied targets that means: active state for kinases, agonist-bound state for GPCRs, ATP-bound state for ATPases, closed state for many transporters.
If you are asking about an inhibitor complex when the model returns an active conformation, the predicted interface is mechanically wrong even if every residue contact looks plausible. The activation loop is in the wrong place; the allosteric pocket is collapsed; the regulatory subunit docks against a surface that is occluded in the relevant state.
This is structurally distinct from "AlphaFold got the fold wrong." The fold is right. The state is wrong. And the state, not the fold, is what determines the interface for many regulatory complexes.
How to recognize it
The predicted state contradicts known biology: an inhibitor is bound, but the kinase is in the catalytically competent conformation.
Mutational data from the literature does not map cleanly onto the predicted interface—loss-of-function mutations are in regions that are far from contact in the prediction but would be at the interface in the alternative state.
Sequence variability analysis (e.g., from ConSurf) flags conserved residues outside the predicted interface, suggesting a different functional surface.
Cryo-EM or crystallographic literature shows the protein in a state different from what AlphaFold returned, even if no complex structure exists.
Workaround
MSA subsampling is the most effective documented intervention. By restricting the MSA to a small number of sequences (typically 32-128 random subsamples), AlphaFold can be coaxed into sampling alternative conformational states. This is now standard practice for kinases and transporters and is described in detail in del Alamo et al. (2022) and the AF-cluster follow-up work. Where the relevant state is known to exist in the PDB for a related protein, supplying a structural template is the most direct intervention.

Failure Mode 4: Antibody-Antigen Complexes
What goes wrong
Antibody-antigen complexes are the canonical hard case. The CDR loops—particularly H3—are hypervariable, the binding interface is shaped by somatic hypermutation rather than evolutionary co-variation, and there is essentially no co-evolutionary signal between antibody and antigen across the lineage. AlphaFold-Multimer's accuracy on antibody-antigen complexes is well documented as substantially worse than for evolutionarily co-evolved partners, with blind benchmarks placing epitope success rates around 20-30% even when ipTM scores look high.
The model's headline confidence metrics are misleading here because the antibody framework folds correctly (which dominates pTM) and one of many surface patches on the antigen can be made to look like a low-PAE interface. But the relative orientation—the angle of approach, the H3 conformation, the precise CDR-paratope contacts—is frequently wrong. Two predictions with similar ipTM can place the paratope on opposite sides of the antigen.
Specialized methods have emerged in response. AlphaFold3 and successors that use diffusion-based sampling generally improve over AlphaFold-Multimer 2 on antibody-antigen, but the problem is not solved.
How to recognize it
Epitope conservation is incompatible with the prediction: known escape mutants cluster elsewhere.
Multiple seeds give visually different epitopes—not minor adjustments but fundamentally different binding sites.
The CDR-H3 loop has anomalously high pLDDT despite being expected to be flexible; the model has chosen one conformation and frozen it.
There is no co-evolutionary support—paired MSAs are essentially impossible for antibody-antigen because immune repertoires do not co-evolve with antigens across species.
Workaround
For antibody design and epitope mapping, treat AlphaFold-Multimer as a tool for filtering, not selecting. Use it to rule out steric impossibilities and to score candidate epitopes against orthogonal evidence (HDX-MS protection maps, alanine scan data, escape mutant panels). For new model variants, including diffusion-based approaches, validate on a held-out internal benchmark with known structures before trusting on novel targets.
Failure Mode 5: Membrane Protein Interfaces
What goes wrong
AlphaFold-Multimer predicts in vacuum. Lipid molecules are absent from the input; the bilayer is absent; cholesterol, PIP2, and cardiolipin—often essential for interface formation—are absent. For GPCR dimers, ABC transporter cooperativity, receptor tyrosine kinase activation, and many membrane signaling assemblies, the lipid environment is a structural element. Removing it changes the answer.
In practice, AlphaFold-Multimer often produces membrane protein interfaces that look correct in transmembrane register and orientation but assign the wrong helices to the dimer interface. A class A GPCR with three plausible dimer interfaces (TM1/TM2, TM4/TM5, TM5/TM6) will be predicted as one of them based on the dominant signal in the training data, which may not match the lipid-organized assembly in your cells.
A second pathology: soluble domain "interfaces" that pull membrane-anchored subunits into geometries that the bilayer would forbid. The cytoplasmic and luminal/extracellular faces dock at angles that require the transmembrane helices to bend or rotate in ways that lipids would prevent.
How to recognize it
The predicted interface buries residues that should face lipid (especially the lipid-exposed face of TM helices). Conserved hydrophobic residues should face lipid; conserved polar residues should face the interior or protein-protein interfaces.
The membrane plane is not parallel to the bilayer normal when both partners are positioned in the predicted assembly.
Inter-chain contacts include residues that are known from biochemistry to be lipid-binding sites.
Asymmetric heterodimers between membrane and soluble subunits show the soluble partner buried into a position that would clash with the membrane surface.
Workaround
Project the predicted structure into a membrane normal using OPM or PPM and check the orientation explicitly. For known lipid-binding sites, screen the predicted interface against lipid-mediated contact databases. When the cytoplasmic partner is large, run the prediction with and without the transmembrane domain to test whether the soluble interface is internally consistent. Cryo-EM in nanodiscs or native lipids remains the gold standard for membrane complex interfaces, and where it exists, it should override the prediction.
Failure Mode 6: Shallow MSA on One Partner
What goes wrong
AlphaFold-Multimer's interface prediction relies on paired MSAs and the co-evolutionary signal they encode. When one partner has a deep MSA (thousands of homologs across phyla) and the other has a shallow MSA (a few dozen sequences, all from closely related species), the paired MSA is effectively as shallow as the worst partner. The model can still fold both chains—the deep-MSA partner constrains its own fold, and the shallow-MSA partner inherits enough information from sequence-only signals to fold reasonably—but the interface, which depends on co-variation, is undersupported.
In this regime, AlphaFold-Multimer tends to produce predictions where the deep-MSA partner is well-folded with low intra-chain PAE, the shallow-MSA partner has moderate confidence overall, and the inter-chain PAE is broadly elevated. The dangerous case is when the model nevertheless converges on a specific interface because the partners happen to have surface complementarity. This is a hallucination in the sense relevant to structural biology: the model has generated a plausible answer in the absence of evidence.
Recent work, including the cluster-based AF-cluster approach and the 2024 AlphaFold3 release, has narrowed but not eliminated this gap.
How to recognize it
MSA depth report shows < 100 paired sequences or a paired MSA dominated by close paralogs.
One partner is orphan-like: lineage-specific (e.g., human-only, viral protein from a recently sequenced family) or de novo designed.
Inter-chain PAE is uniformly elevated (>15 Å) across the entire matrix without the islands of confidence that mark a real but partial signal.
ipTM is low (<0.6) even though pTM is reasonable.
Workaround
Before trusting the prediction, examine the MSA depth on both partners. If the paired MSA is shallow, treat the prediction as exploratory. Where homologous structures exist for either partner in complex with anything, supplying templates can rescue prediction quality. For viral or de novo proteins, language-model-based co-folding methods (which do not depend on MSA depth in the same way) may produce more useful predictions, but require independent validation.
Diagnostic Table: Failure Mode, Signal, and Workaround
Failure Mode | Diagnostic Signal | Primary Workaround |
|---|---|---|
Transient / weak complex (Kd > μM) | ipTM 0.5–0.7; patchy off-diagonal PAE; top-5 models disagree | Multi-seed consensus; HDX-MS or XL-MS validation |
Wrong stoichiometry | Inconsistent SEC-MALS / native MS mass; broken symmetry; small per-subunit interface | Stoichiometry sweep guided by biophysical mass measurement |
Conformational state mismatch | Conserved residues outside predicted interface; literature shows state mismatch | MSA subsampling; structural templates of correct state |
Antibody-antigen | Epitope contradicts escape mutants; multiple seeds give different epitopes | Diffusion-based methods; orthogonal experimental constraints |
Membrane interface | Hydrophobic residues face protein instead of lipid; bilayer geometry violated | OPM/PPM projection; nanodisc cryo-EM |
Shallow MSA on one partner | Paired MSA depth < 100; uniformly high inter-chain PAE; low ipTM despite folded chains | Template injection; co-folding language models; validation experiments |
Confidence Metric Interpretation in the Context of Failure Modes
The interaction between confidence scores and failure modes is what makes AlphaFold-Multimer interpretation hard. A high confidence score does not exclude failure; it conditions on the assumption that the input prompt (sequences, stoichiometry, no explicit state, no lipids) is well-posed.
Metric | High-Confidence Interpretation | What It Cannot Detect |
|---|---|---|
pLDDT > 90 (per chain) | Each chain folds well individually | Wrong stoichiometry; wrong state; wrong interface |
Intra-chain PAE < 5 Å | Domain architecture is reliable | Allosteric or substrate-induced rearrangements |
Inter-chain PAE < 10 Å at interface | Interface geometry is internally consistent | Whether this is the biological interface |
ipTM > 0.8 | Strong network-internal interface support | Antibody-antigen failure; transient complex hallucination; lipid-mediated alternative |
pTM > 0.7 | Globally plausible assembly | Stoichiometry, state, environment |
The single most useful operational rule is: a high ipTM is a necessary but not sufficient condition for a trustworthy complex prediction. Failure modes 1, 2, 3, 4, 5, and 6 can all coexist with ipTM > 0.7.

Case Study: The Kinase-Scaffold That Wasn't
The Setup
A mid-sized academic group studying a poorly characterized scaffolding protein wanted to map its interaction with a Ser/Thr kinase implicated in stress signaling. They had:
Robust co-IP from cell lysates.
A clean GST pull-down with recombinant protein.
Mass-spec evidence of phosphorylation on the scaffold.
They ran AlphaFold-Multimer in 1:1 heterodimer mode. The result was striking: ipTM = 0.74, pTM = 0.81, both chains at pLDDT > 85. The 3D viewer showed the kinase active-site cleft facing a beta-hairpin on the scaffold, with several residues making canonical hydrogen-bond contacts. It looked like a textbook substrate-binding pose.
The Investment
The group designed 18 mutants on the predicted interface: alanine scans on the scaffold beta-hairpin, charge reversals on the kinase active-site rim, and a triple mutant intended to abolish binding. Each mutant was expressed in E. coli, purified by Ni-NTA and SEC, and characterized by SPR for binding to wild-type partner.
The Result
After six months: every single mutant bound the wild-type partner with Kd indistinguishable from wild-type. The triple mutant—predicted to ablate binding entirely—bound with 1.3-fold weaker affinity, well within experimental noise.
The Post-Mortem
Three failure modes were operating simultaneously.
Stoichiometry: SEC-MALS performed retroactively showed the scaffold is a stable homodimer in solution. The "1:1 heterodimer" prompt was wrong; the relevant assembly is A₂B.
Conformational state: The kinase was predicted in its active, DFG-in conformation. The scaffold-binding biology, recovered from a later proteomics paper, occurs only on the inactive, DFG-out form.
Shallow MSA on the scaffold: The scaffold is a metazoan-specific protein with fewer than 200 paired sequences against the kinase. Co-evolutionary signal was minimal.
The real interface, discovered later by HDX-MS, was on the back side of the scaffold and required the kinase activation loop to be disordered. AlphaFold-Multimer had stitched together a plausible-looking but biologically fictional pose from features that survive in its training distribution.
What Would Have Prevented This
A 30-minute stoichiometry sweep (A:B, A₂:B, A₂:B₂) would have surfaced that A₂:B had substantially higher ipTM than A:B. A multi-seed run would have shown that two of the five seeds placed the interface in a completely different location. A reading of the kinase's literature would have established that the relevant biology is on the inactive state, which an MSA-subsampled run could have produced.
Total preventive work: roughly two days of analysis. Saved: six months of mutagenesis.
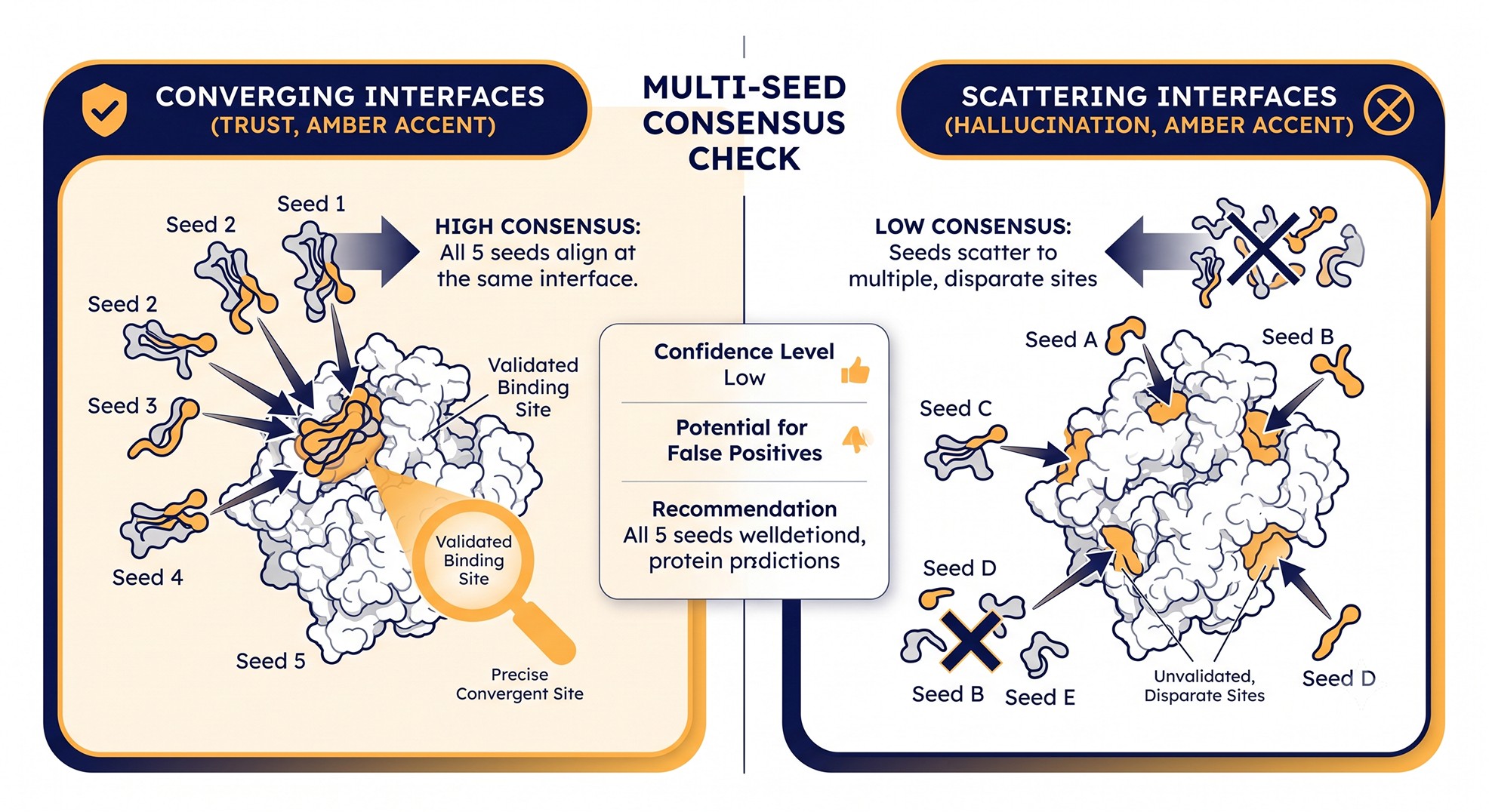
Multi-Seed Consensus: The Cheapest Robustness Check
For about 10x the compute of a single run, multi-seed analysis catches a large fraction of these failure modes before they reach downstream experiments.
The protocol is straightforward:
Run AlphaFold-Multimer with five different random seeds (or use a single run with 5 model rankings).
For each pair of predictions, compute interface RMSD using the contact residues.
If inter-prediction RMSD is < 4 Å, the interface is consistent. If > 8 Å, the model is hallucinating—different seeds find different "best" interfaces.
Humphreys et al. (2021), in their proteome-wide complex prediction work, used a similar consistency-across-models heuristic as a filter and found that it correlates better with experimental validation than any single confidence metric.
This single check would have prevented the kinase-scaffold story that opens this article.
When AlphaFold-Multimer Excels: The Other Side of the Ledger
A failure-modes article risks giving the impression that AlphaFold-Multimer cannot be trusted at all. That is not the right reading. There are regimes where the model is genuinely excellent, and recognizing them is as important as recognizing the failure modes.
Obligate, Evolutionarily Conserved Heterodimers
Complexes that have co-evolved for hundreds of millions of years—ribosomal protein contacts, RNA polymerase subunits, proteasome subunits, the F1-ATPase rotor-stator interface—are predicted with near-experimental accuracy. The combination of deep MSAs, paired co-evolutionary signal, and abundant homologous structures in the PDB pushes the success rate above 90% for this class. If your complex looks like one of these, the prediction is usually a faithful guide.
Eukaryotic Multi-Subunit Complexes Built From Conserved Modules
The Humphreys et al. (2021) work demonstrated that combining AlphaFold-Multimer with proteomics-derived interaction evidence can reconstruct large eukaryotic complexes—nuclear pore subcomplexes, splicing factor cores, transcriptional regulators—with high fidelity. The lesson: when AlphaFold-Multimer is anchored in independent biochemical evidence and applied to conserved assemblies, it scales remarkably well.
Enzyme-Inhibitor and Enzyme-Cofactor Pairs With Homologous Structures
If a related enzyme has been co-crystallized with a homologous inhibitor or cofactor, AlphaFold-Multimer typically transfers that binding mode accurately. This is essentially template-driven prediction in disguise—the network has memorized the binding pose from its training set—and is reliable as long as the relevant chemistry is similar enough.
What These Cases Have in Common
Three properties recur:
Deep paired MSAs.
Conserved interface biology (not lineage-specific).
Homologous structures in the training distribution.
When all three hold, ipTM > 0.8 is genuinely meaningful. When even one fails, ipTM becomes uninformative and the failure-mode checks become mandatory.
Decision Tree: Should You Trust This Prediction?
Practical Pre-Flight Checklist for Any AlphaFold-Multimer Run
Before submitting a complex prediction, work through this checklist. Each item takes minutes and prevents hours of downstream pain.
Inputs
Both sequences are full-length and include all expected domains (no accidental truncation).
Signal peptides, propeptides, and inhibitory prodomains are handled deliberately (kept or removed based on biology, not by default).
Stoichiometry is justified by biophysics (SEC-MALS, mass photometry, AUC, native MS) or by literature, not assumed.
For homo-oligomers, the symmetry expectation is stated explicitly (C₂, C₃, D₂, etc.).
MSA
Paired MSA depth is checked and reported for the actual species and partner combination submitted.
If one partner is orphan-like, this is acknowledged in the interpretation plan.
For state-sampling work, an MSA-subsampling protocol is planned, not improvised after the fact.
Outputs
All five ranked models are inspected, not just rank_1.
Inter-chain PAE is visualized for all top models, not just summarized as a number.
Interface residues are identified and cross-checked against conservation, known binding-site annotations, and PTM data.
Multi-seed RMSD across rankings is computed and reported as a sanity check.
Downstream Decisions
Mutagenesis is not committed to until the interface passes consensus and biophysical sanity checks.
When uncertainty remains, orthogonal experimental data (HDX-MS, XL-MS, NMR CSP) is planned before structural commitments.
If the prediction will appear in a manuscript, the diagnostic figures (PAE matrices, multi-seed comparison) are prepared for the supplement.
The checklist is mundane on purpose. Most AlphaFold-Multimer failures are not exotic—they are failures of process.
The Bottom Line
Question | Honest Answer |
|---|---|
Is AlphaFold-Multimer good enough to skip experiments? | No, except for the most evolutionarily supported cases (obligate complexes with deep MSAs and known stoichiometry). |
Can I trust an ipTM > 0.8 prediction? | Sometimes. Only after multi-seed consistency, stoichiometry, and state checks. |
Is high pLDDT enough? | No. pLDDT is a per-chain metric and is uninformative about the interface. |
Should I run multiple seeds? | Always. The 10x cost is the cheapest insurance available. |
Is antibody-antigen reliable? | No. Treat all antibody-antigen predictions as hypotheses. |
Are membrane complexes reliable? | Rarely. Lipid-mediated and lipid-occluded interfaces are systematically missed. |
The throughline: AlphaFold-Multimer is a powerful sampler, not an oracle. Treat it as a fast, opinionated experimentalist whose intuitions are excellent in the regimes it has seen and unreliable outside them. Build that mental model and the failures stop being surprises.
Diagnosing Failure Modes in Practice
Most labs do not have time to write per-pair scripts for stoichiometry sweeps, MSA-depth audits, multi-seed RMSD analysis, and interface mapping. Orbion's PAE Insight Engine ingests AlphaFold-Multimer outputs and runs these diagnostics in a unified view—per-chain pLDDT histograms, inter-chain PAE with interface highlighting, ipTM/pTM with confidence regime labeling, and per-seed consensus scoring side-by-side. The AlphaFold-Multimer integration also exposes stoichiometry sweeps as a one-click operation, so testing A₂B versus A₃B₂ takes minutes rather than hours of submission and re-parsing. For users focused on interfaces, AstraBIND maps predicted contact residues against known binding-site annotations, conserved surface patches, and PTM-modifiable positions so that an interface flagged as "high confidence" can be cross-checked against orthogonal evidence before mutagenesis. The point is not to replace structural intuition but to surface the diagnostics that prevent the six failure modes above from becoming six months of bench work.
References
Evans R, O'Neill M, Pritzel A, et al. (2022). Protein complex prediction with AlphaFold-Multimer. bioRxiv. Link
Bryant P, Pozzati G, Elofsson A. (2022). Improved prediction of protein-protein interactions using AlphaFold2. Nature Communications, 13:1265. Link
Yin R, Feng BY, Varshney A, Pierce BG. (2022). Benchmarking AlphaFold for protein complex modeling reveals accuracy determinants. Protein Science, 31(8):e4379. Link
Burke DF, Bryant P, Barrio-Hernandez I, et al. (2023). Towards a structurally resolved human protein interaction network. Nature Structural & Molecular Biology, 30:216-225. Link
Humphreys IR, Pei J, Baek M, et al. (2021). Computed structures of core eukaryotic protein complexes. Science, 374(6573):eabm4805. Link
Akdel M, Pires DEV, Pardo EP, et al. (2022). A structural biology community assessment of AlphaFold2 applications. Nature Structural & Molecular Biology, 29:1056-1067. Link
Book a 20-Minute Demo
Sign up free for unlimited Overview runs — summary, sequence-based analysis, homology search. For the full Characterization — PTMs, binding sites, stability variants, construct design — book a demo and we'll run your target live.
